Consumer GPUs can reliably replace cloud inference for most SME workloads, except latency-critical long-context RAG, where high-end GPUs remain essential.
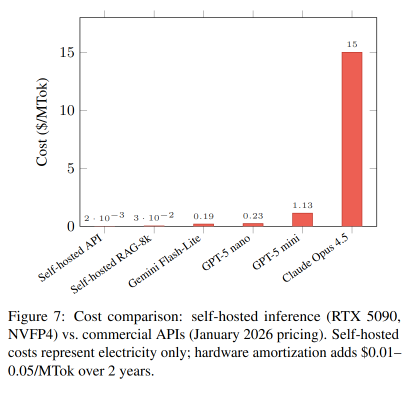
Self-hosted inference achieves cost parity with commercial APIs within 1–4 months at moderate usage (30M tokens/day), with subsequent operation at 40–200× lower cost than budget-tier cloud models.
Private LLM Inference on Consumer Blackwell GPUs: A Practical Guide for Cost-Effective Local Deployment in SMEs
https://arxiv.org/abs/2601.09527
"a systematic evaluation of NVIDIA's Blackwell consumer GPUs (RTX 5060 Ti, 5070 Ti, 5090) for production LLM inference, benchmarking four open-weight models"
"Consider dual-GPU configurations for consistent 32k+ workloads"
"Long-context benchmarks beyond 64k remain incomplete due to memory constraints."